


What We Did
Replaced standard recurrent memory with CogRNN, a memory module based on Laplace-domain encoding and approximate inverse reconstruction.
AAAI 2025 | Proceedings of the AAAI Conference on Artificial Intelligence
Department of Computer Science, Luddy School of Informatics, Computing, and Engineering, Indiana University Bloomington
A neuroscience-inspired memory mechanism that allows RL agents to retain robust performance when temporal structure in the environment is rescaled.
Temporal credit assignment is difficult for both biological and artificial agents, especially when the same task appears at different time scales. This work integrates a scale-invariant memory model into deep reinforcement learning and demonstrates strong, stable learning across temporally rescaled conditions. The key idea is to build a log-compressed memory of past inputs so that temporal rescaling appears as translation in internal state, reducing the need to retune agents for each scale.
Replaced standard recurrent memory with CogRNN, a memory module based on Laplace-domain encoding and approximate inverse reconstruction.
Animal timing behavior is approximately scale invariant, while typical RL memory models often learn in a scale-dependent way.
CogRNN agents maintain high performance and more consistent learning speed across task scales, with temporal activity patterns that align with scale-invariant coding principles.
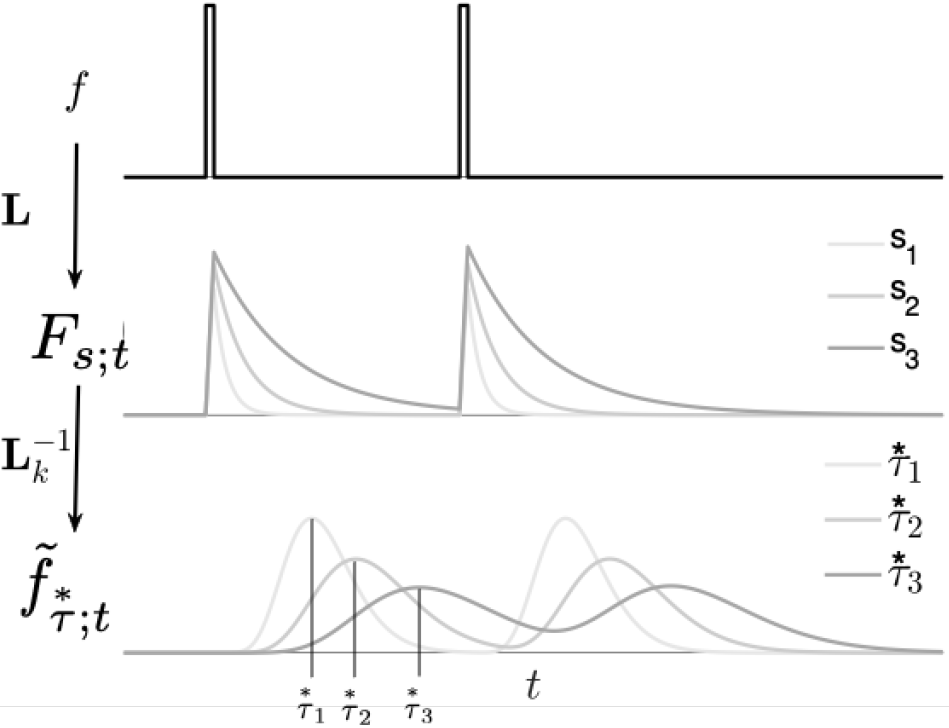
Let $f(t)$ denote encoded observations over time. CogRNN builds a bank of exponentially decaying traces, equivalent to a real-domain Laplace transform, then applies an analytic inverse approximation to recover a sequence of temporal basis functions $\tilde{f}$ over log-spaced internal time constants.
The first stage accumulates history using exponentially weighted traces over a spectrum of decay rates $s$.
Small $s$ keeps long-range context; large $s$ emphasizes recent input.
The same transform can be written as a linear differential equation, which is convenient for recurrent implementation.
This shows a simple decay-plus-drive process at each temporal scale.
The second stage reconstructs a temporally localized code from Laplace-domain traces.
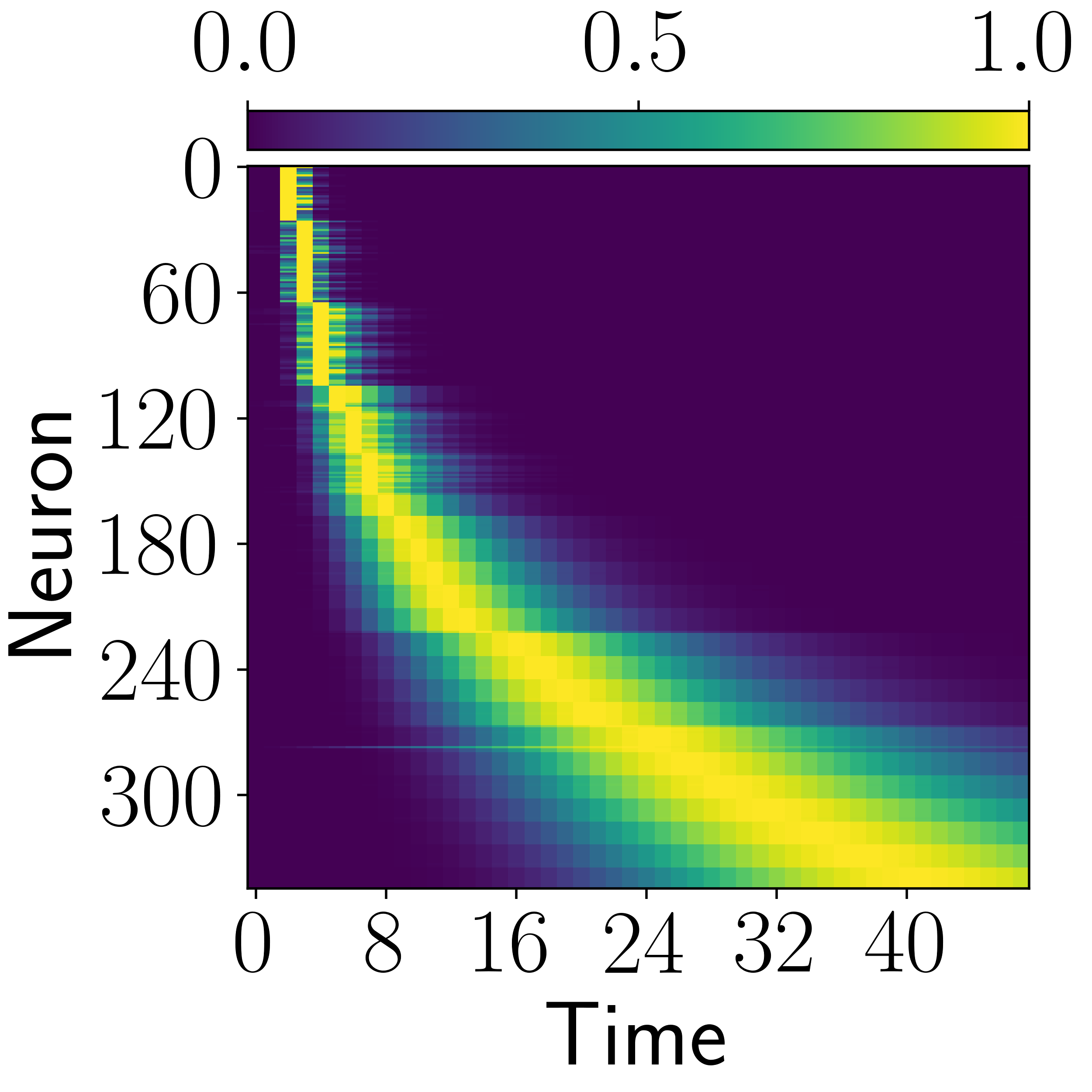
Using $\overset{*}{\tau}=k/s$, units tile time on a compressed axis and support sequential time-cell-like activity.
For neural networks, the memory update is implemented directly as a recurrence.
The diagonal operator $\mathbf{L}$ stores analytically chosen decay rates across memory channels.
This expression describes the temporal profile of each reconstructed unit.
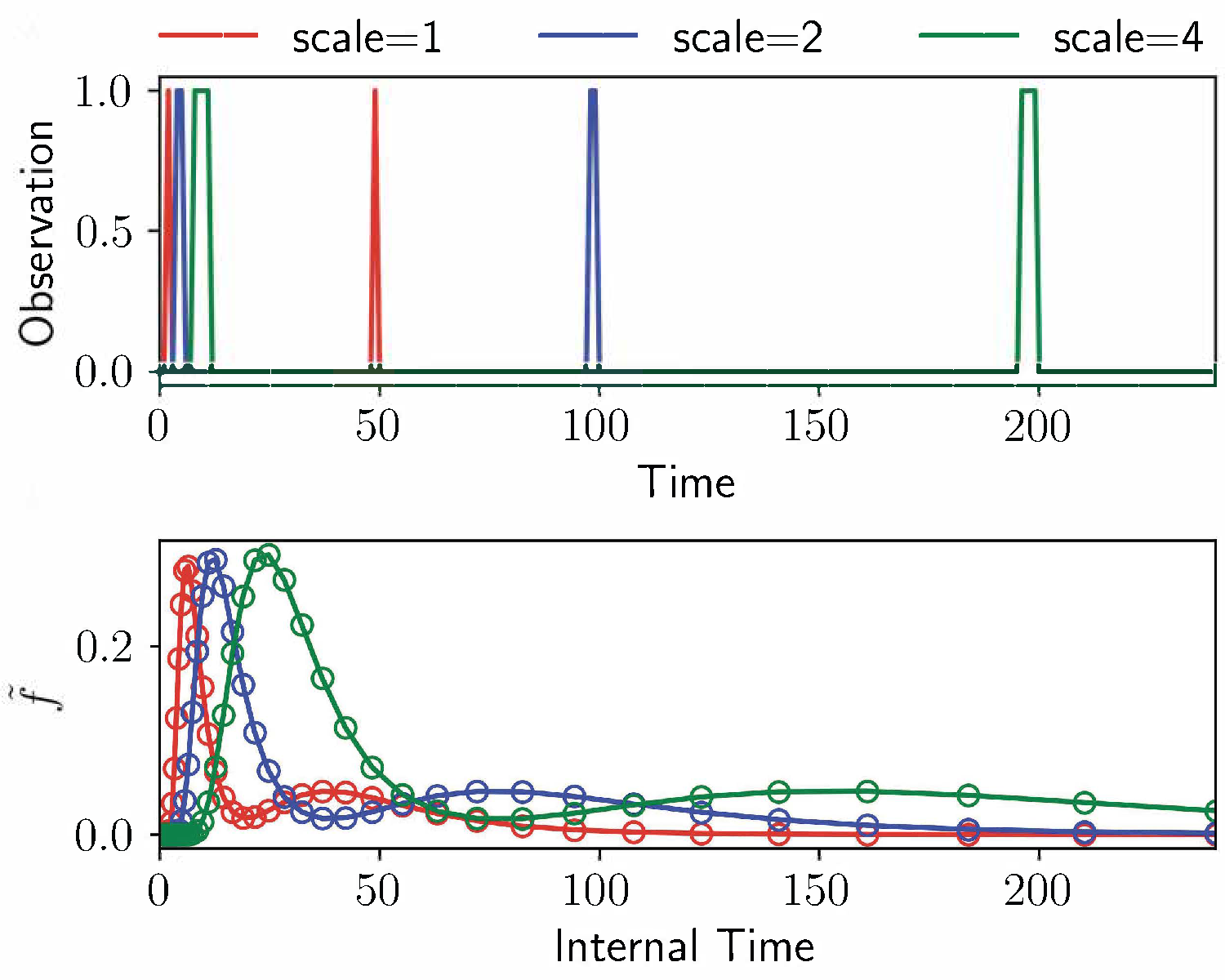
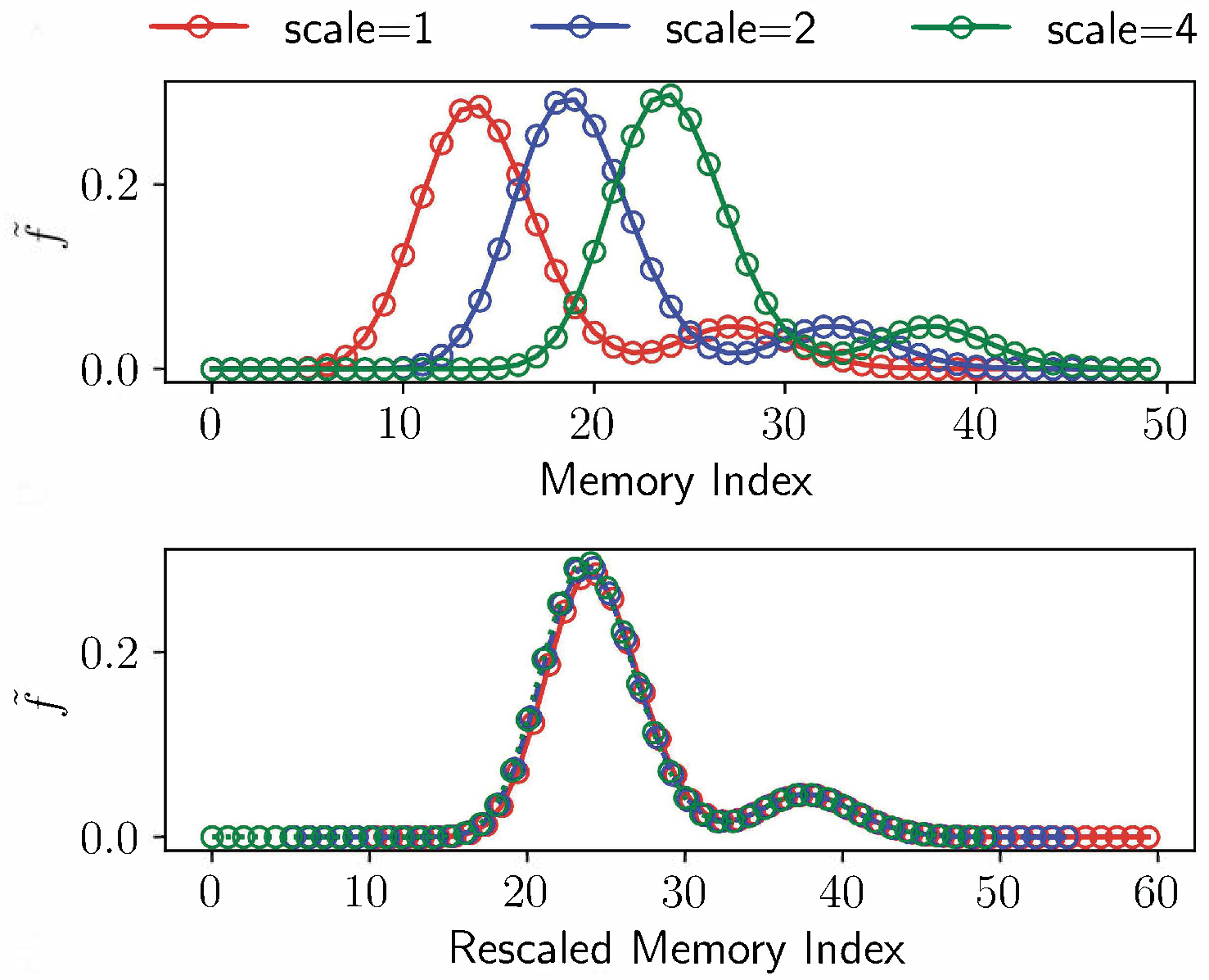
With log-spaced $\overset{*}{\tau}$ values, temporal rescaling in the input produces an approximately constant index shift in memory coordinates; this translation-like behavior is why downstream policies can preserve performance across scales instead of relearning separate dynamics for each temporal stretch factor.
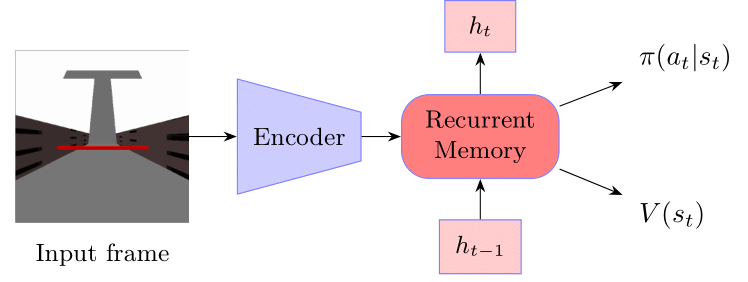
The RL agent architecture consists of three components:


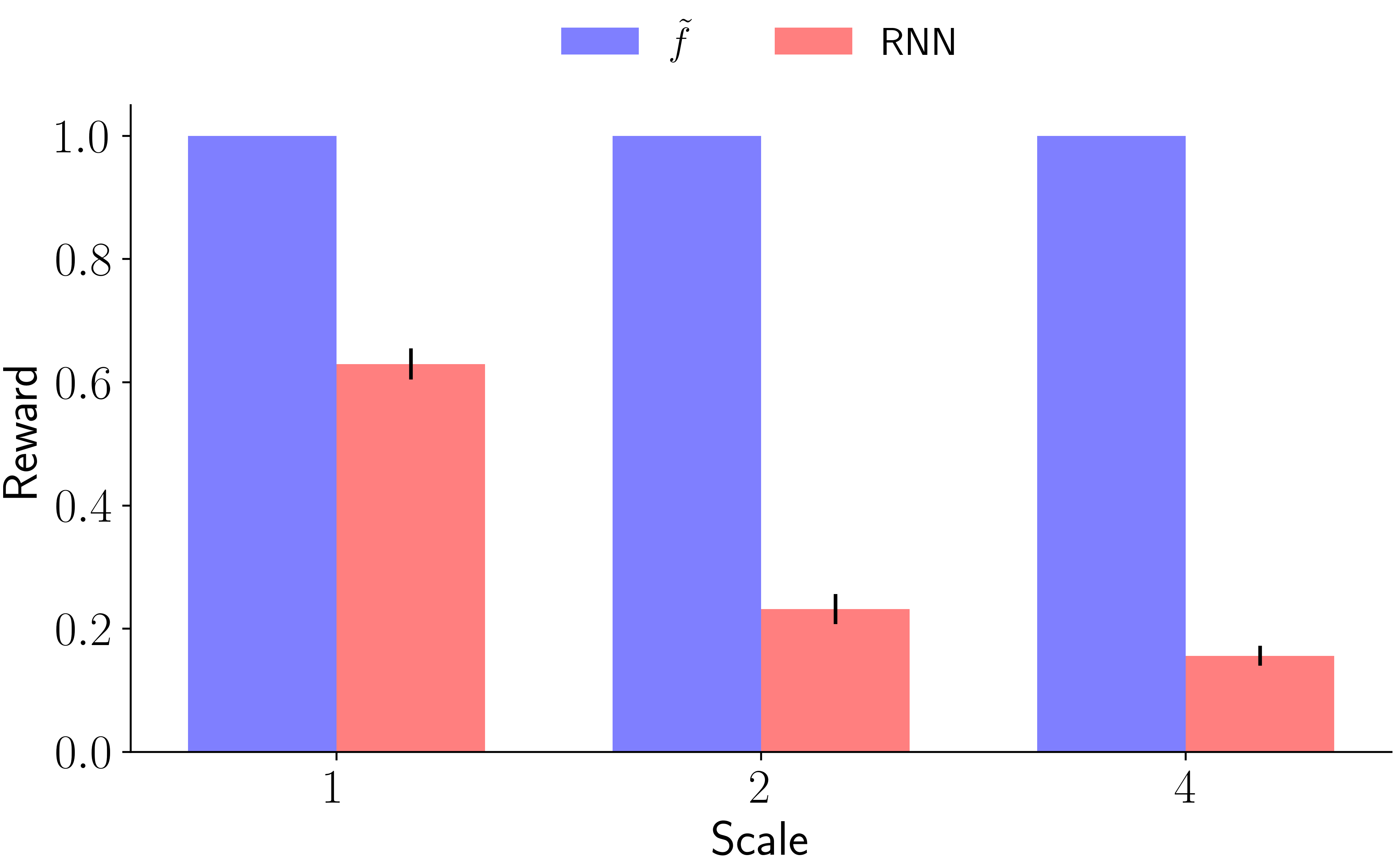
Across four tasks, CogRNN shows consistently strong performance under rescaling. LSTM learns in several settings but exhibits stronger scale dependence, especially in harder conditions.
CogRNN
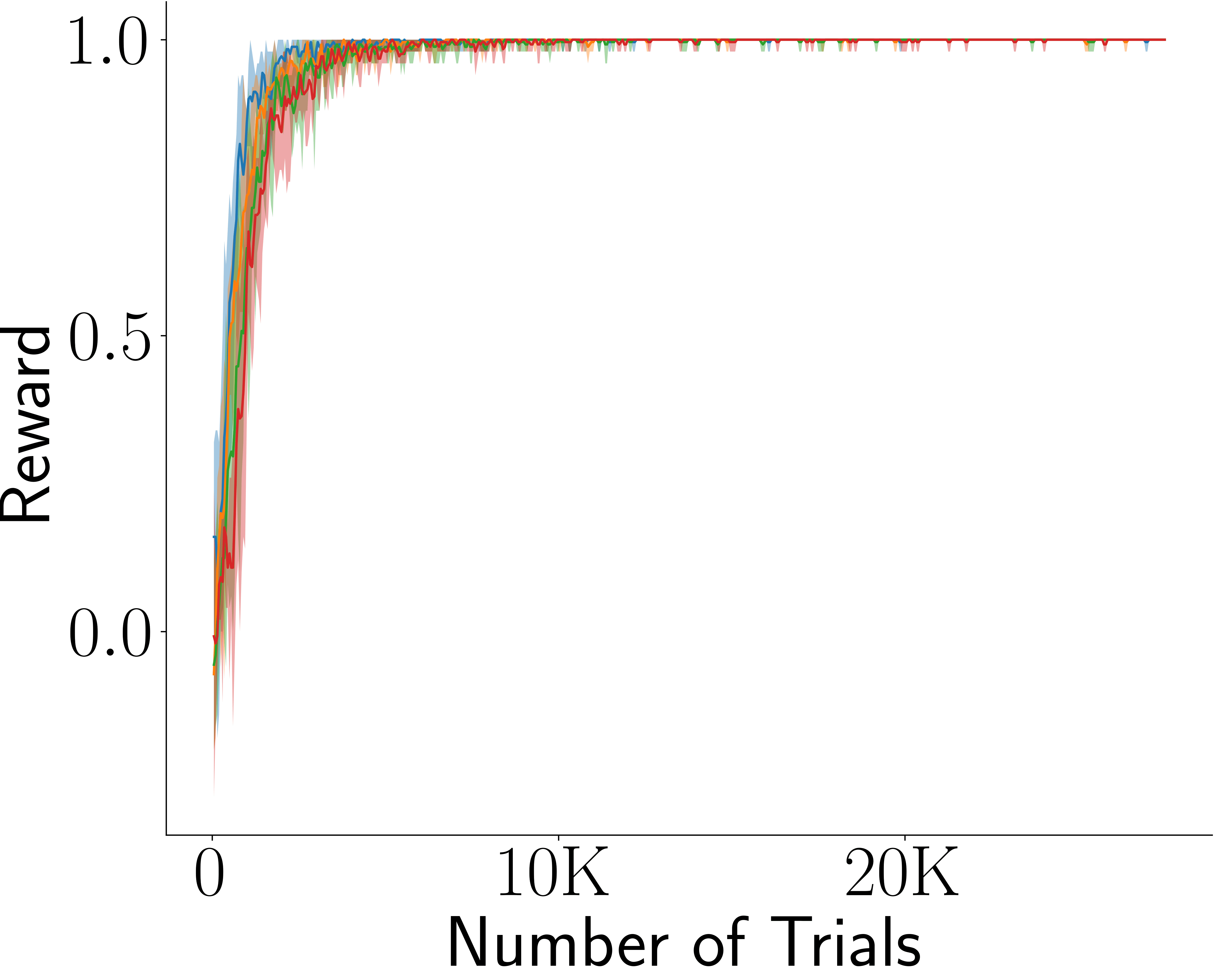
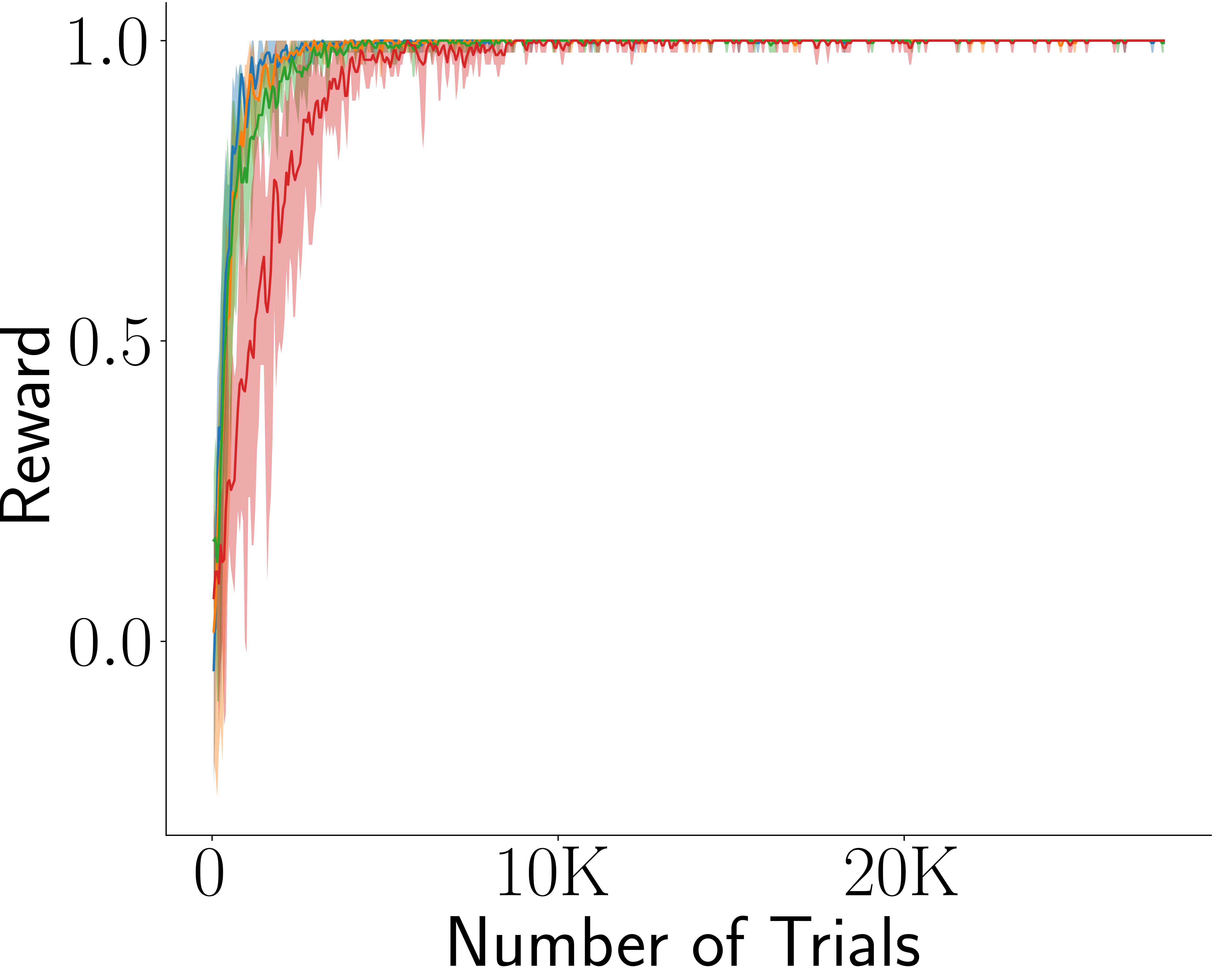
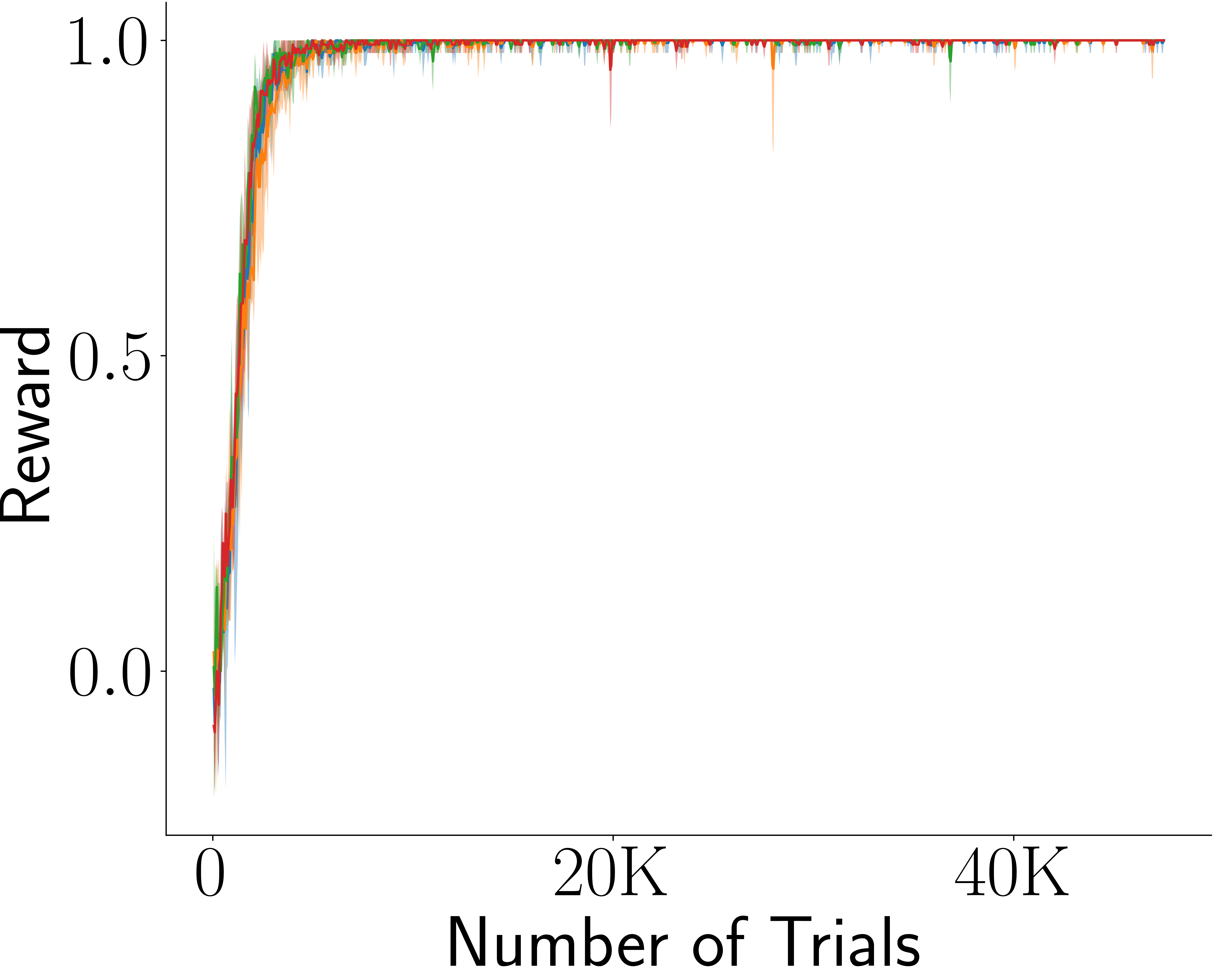
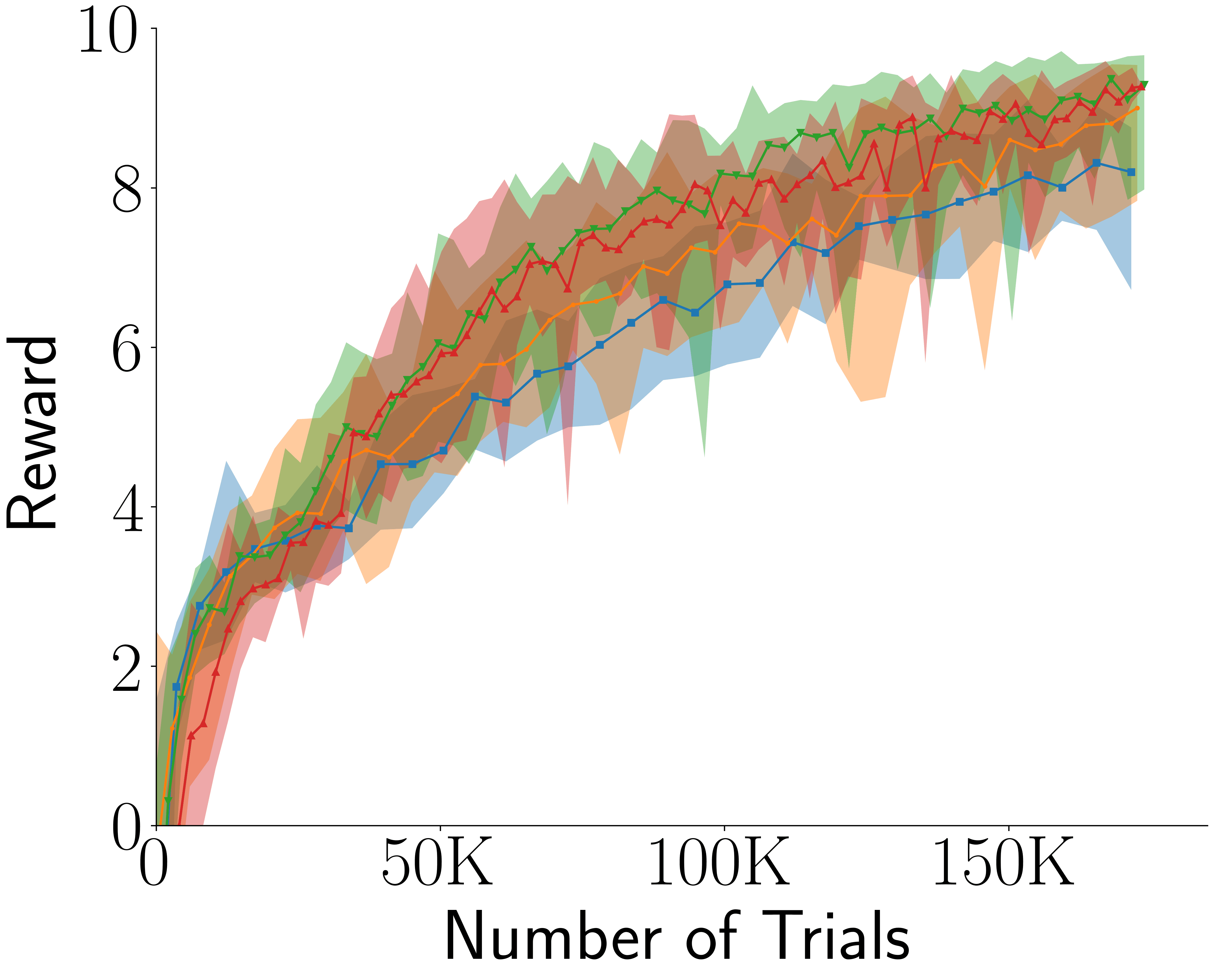
LSTM
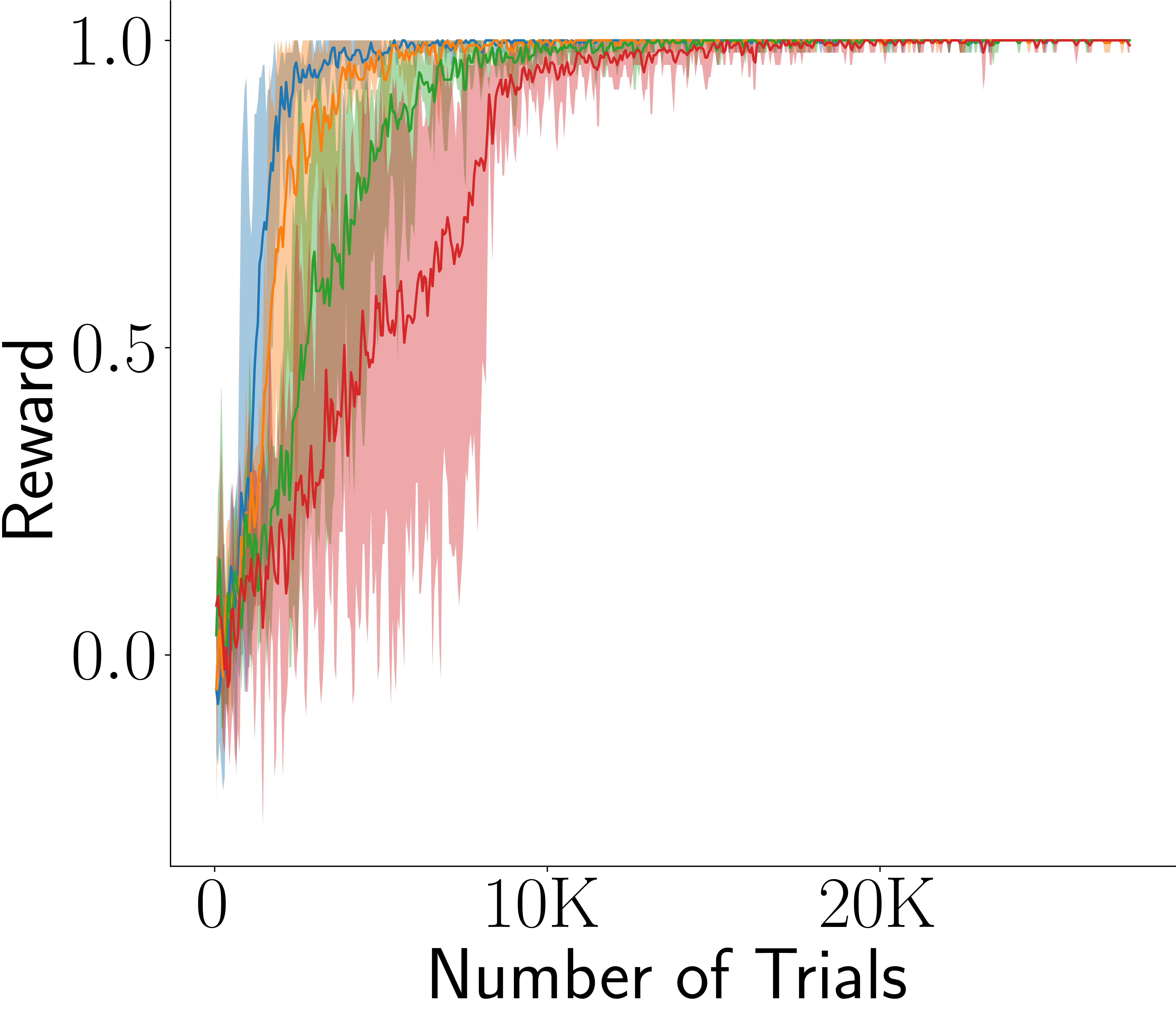
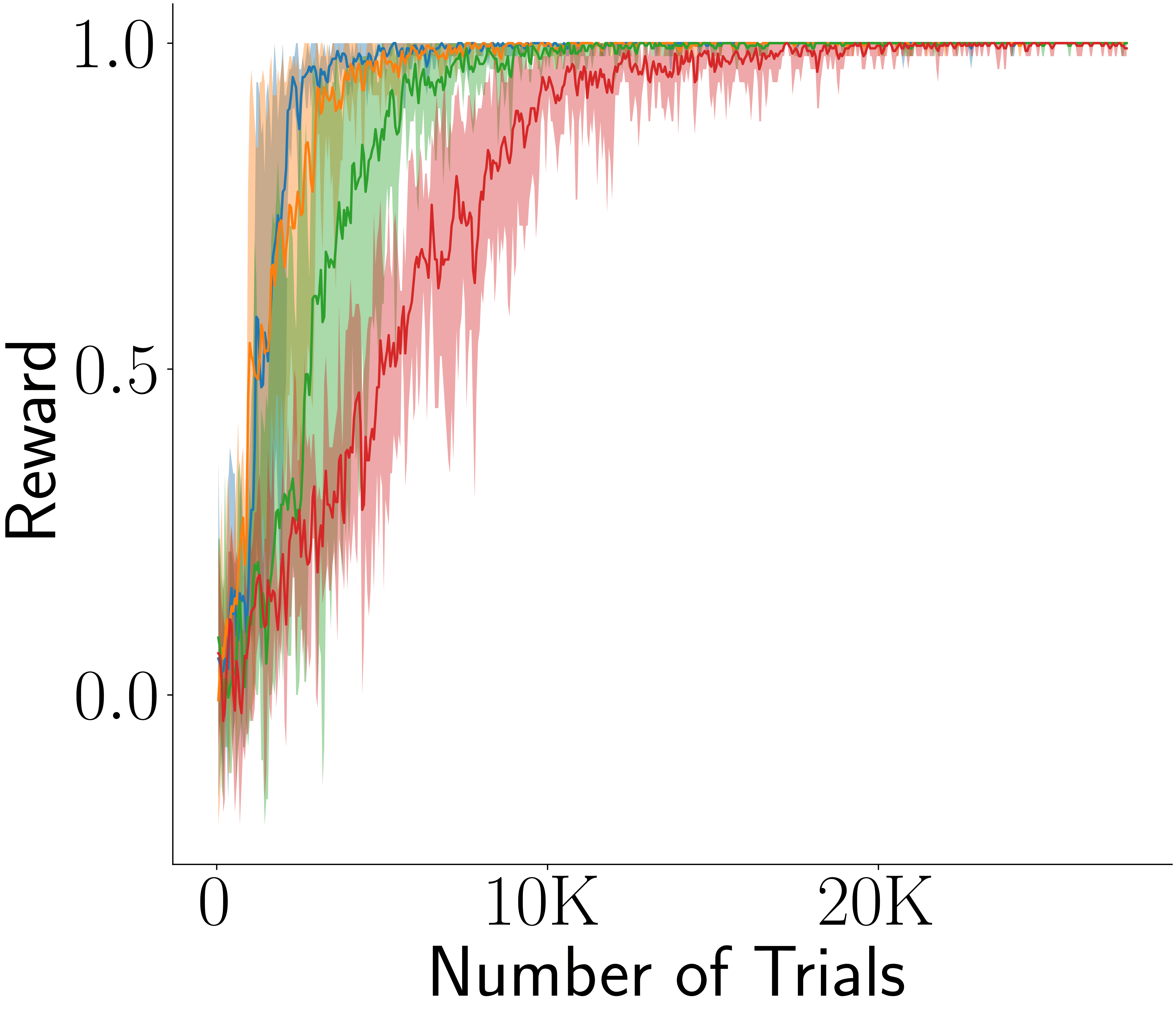
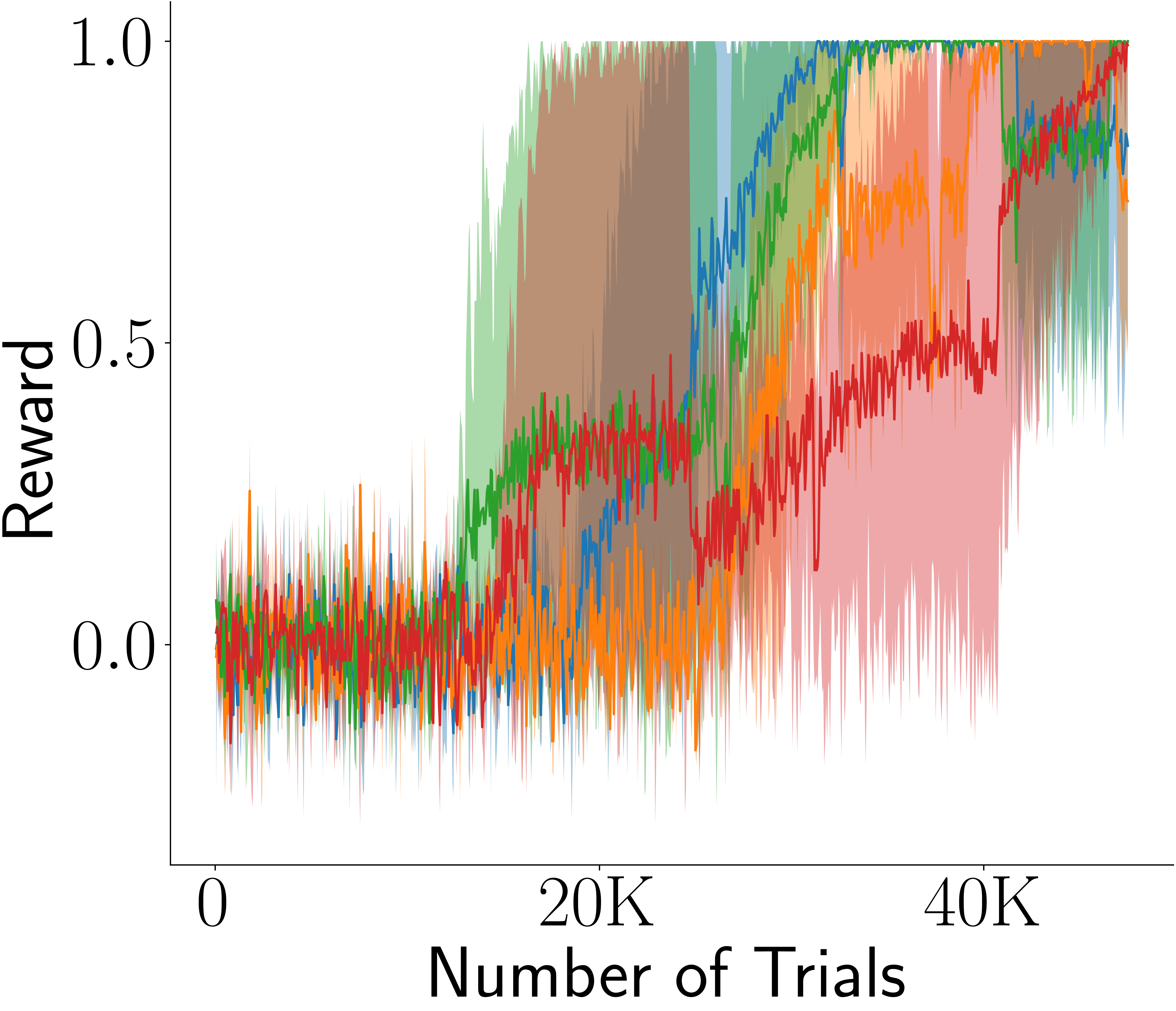
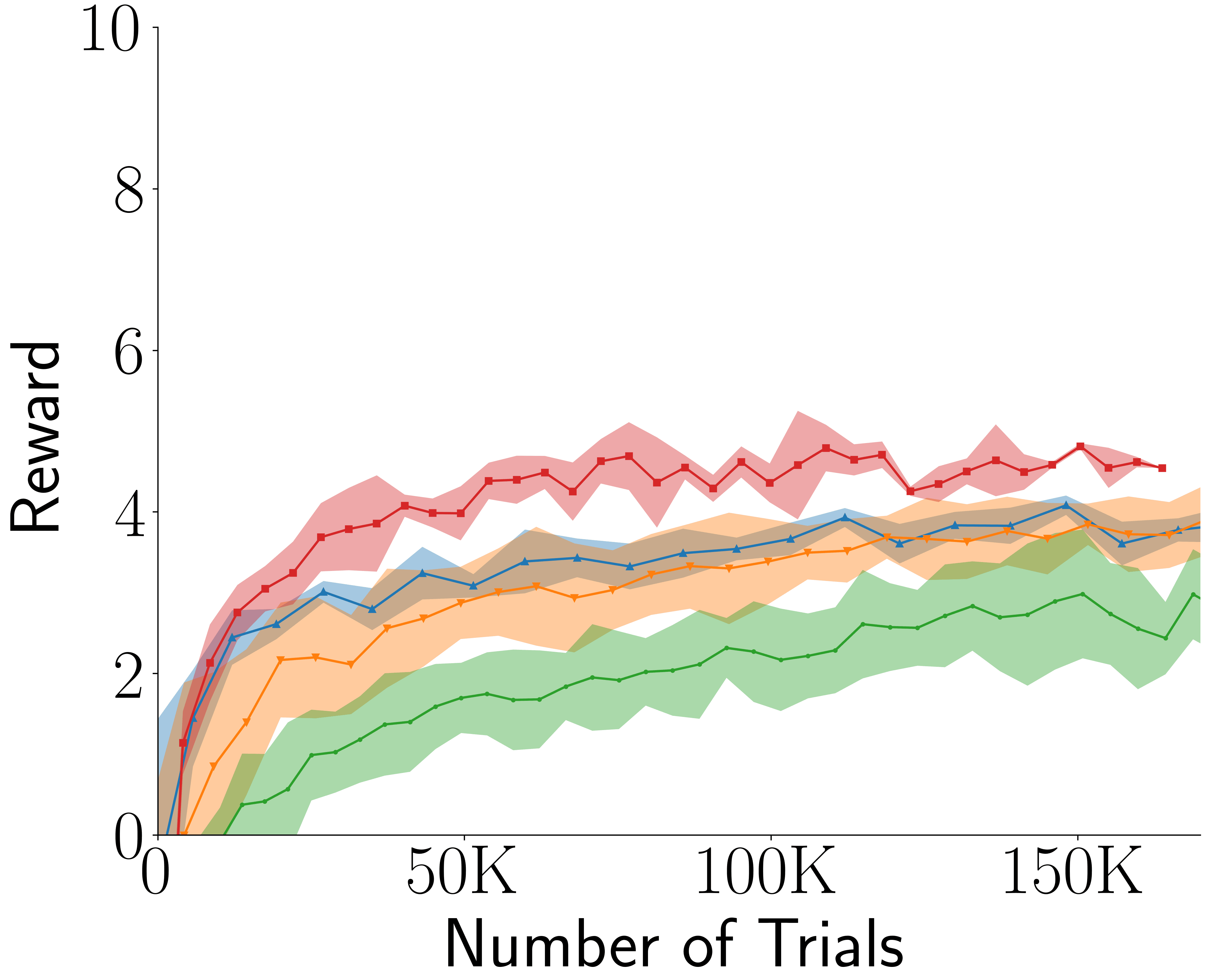

Memory traces are covariant under temporal rescaling (shift in internal coordinates). Convolution and pooling convert this into approximate invariance, allowing transfer from one scale to others without re-optimizing policy dynamics from scratch.

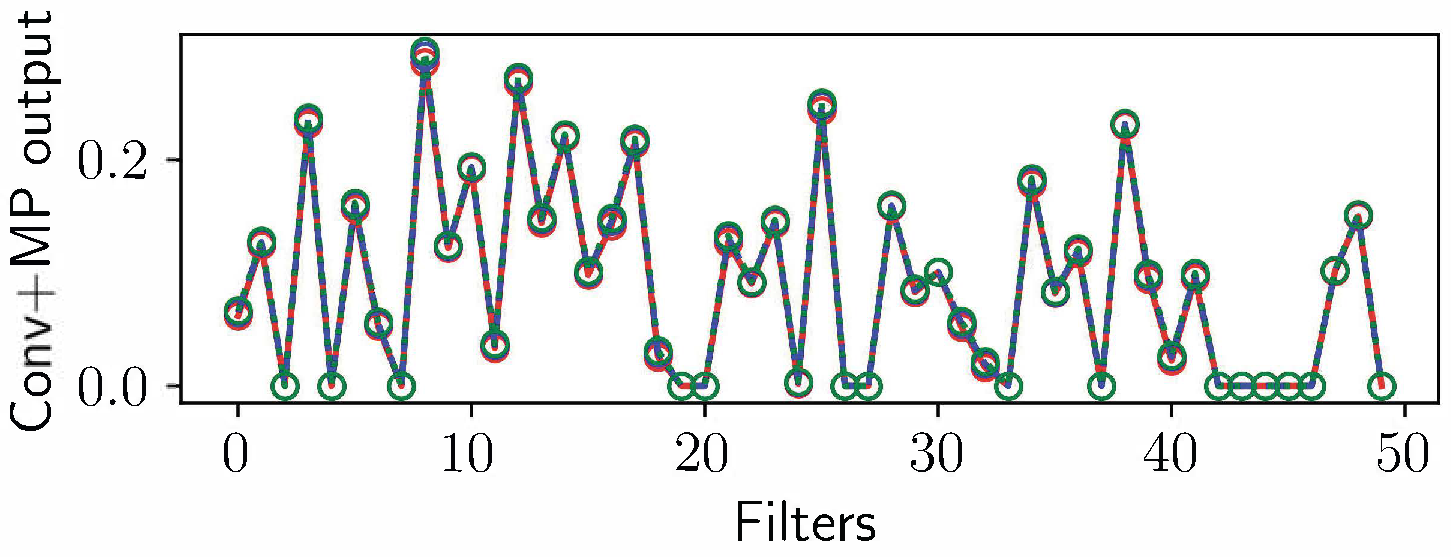
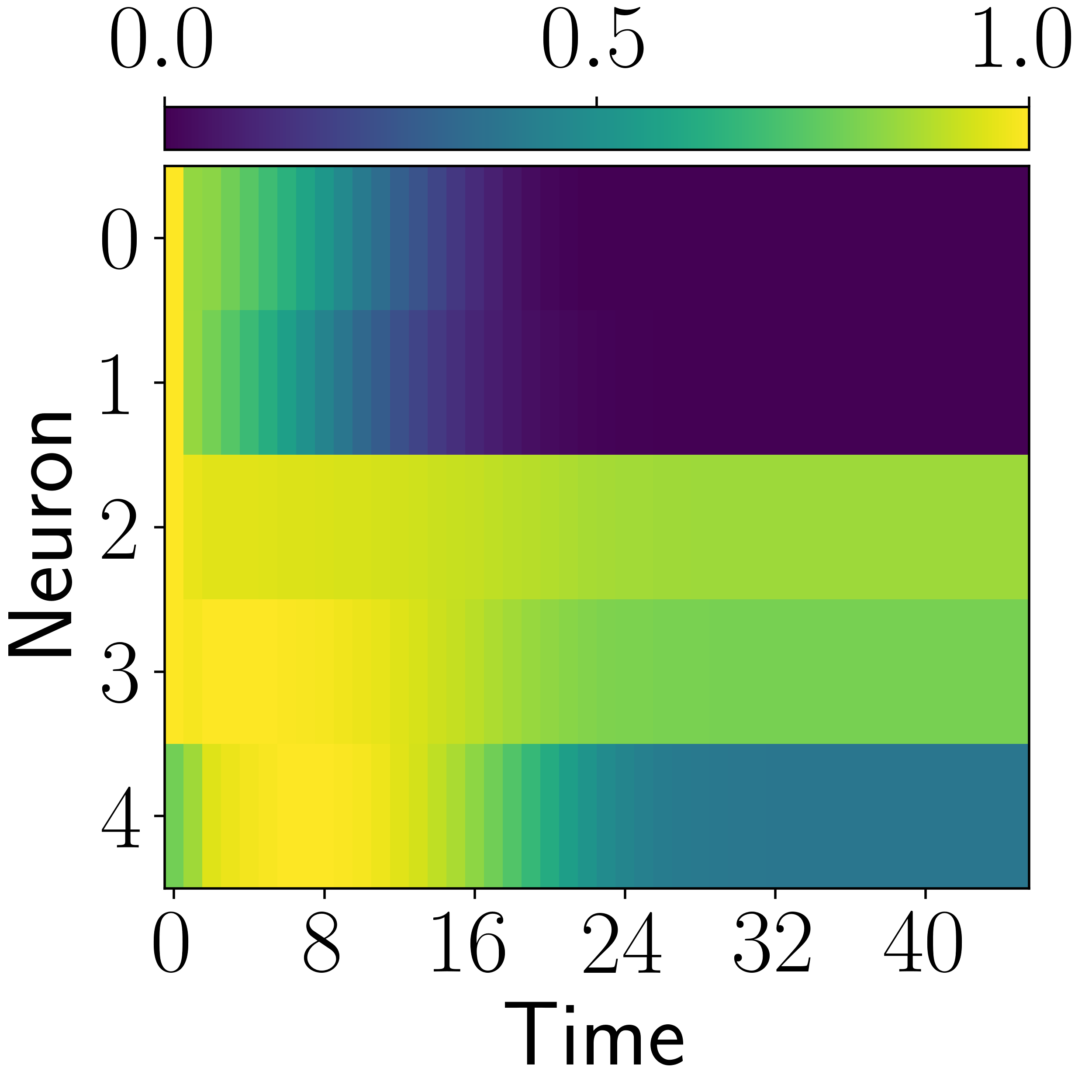
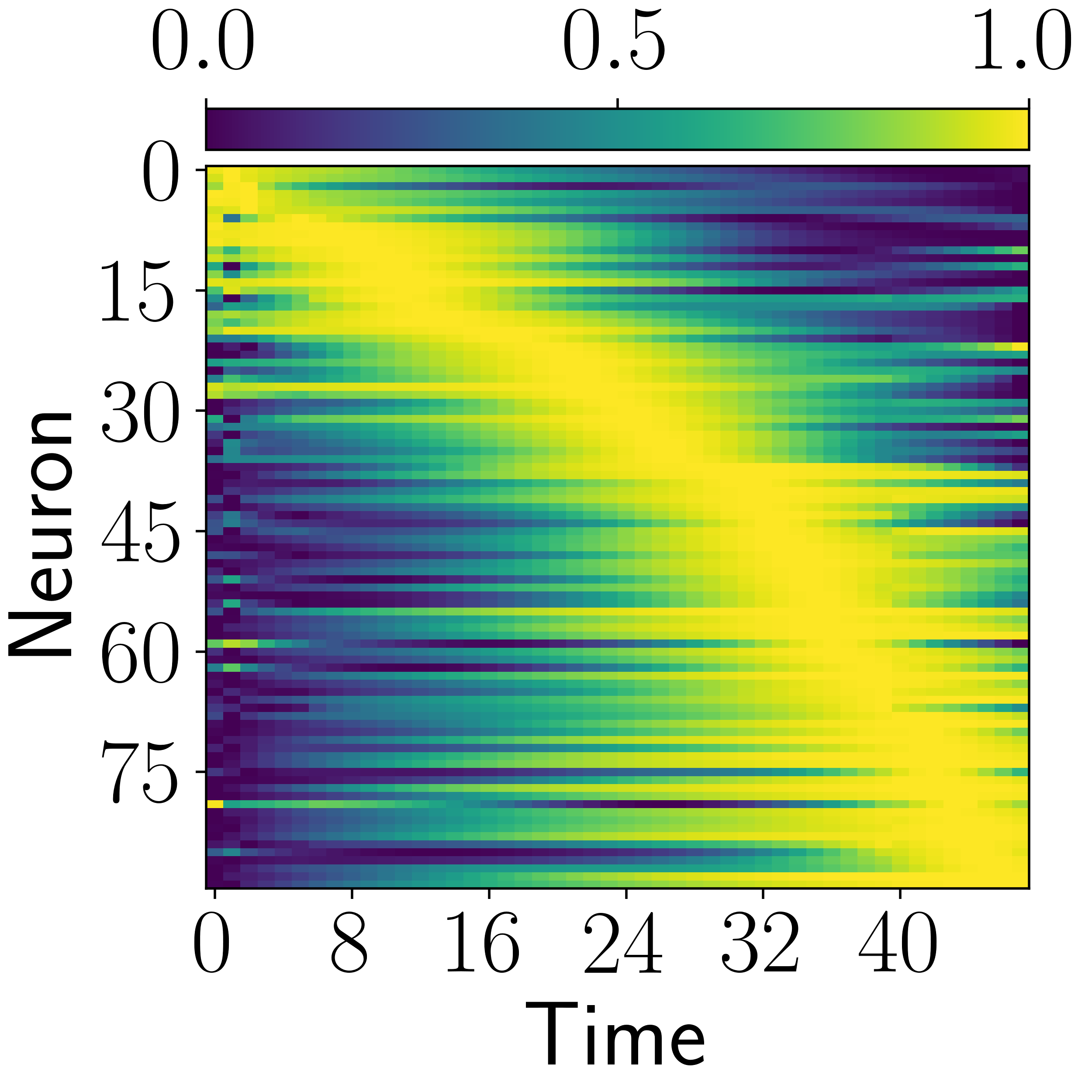
Time-cell-like responses appear in multiple architectures, but CogRNN shows the clearest log-compressed temporal progression consistent with the intended representation geometry.
This research demonstrates that incorporating computational principles from neuroscience into deep learning architectures can enhance their adaptability and robustness. Scale-invariant representations may be crucial for developing AI systems that can flexibly adjust to new environments without extensive hyperparameter tuning - much like biological organisms navigate the world across vastly different spatial and temporal scales.
If this work helps your research, please cite:
@article{Kabir_Mochizuki-Freeman_Tiganj_2025,
title={Deep Reinforcement Learning with Time-Scale Invariant Memory},
volume={39},
url={https://ojs.aaai.org/index.php/AAAI/article/view/32124},
DOI={10.1609/aaai.v39i2.32124},
abstractNote={The ability to estimate temporal relationships is critical for both animals and artificial agents. Cognitive science and neuroscience provide remarkable insights into behavioral and neural aspects of temporal credit assignment. In particular, scale invariance of learning dynamics, observed in behavior and supported by neural data, is one of the key principles that governs animal perception: proportional rescaling of temporal relationships does not alter the overall learning efficiency. Here we integrate a computational neuroscience model of scale invariant memory into deep reinforcement learning (RL) agents. We first provide a theoretical analysis and then demonstrate through experiments that such agents can learn robustly across a wide range of temporal scales, unlike agents built with commonly used recurrent memory architectures such as LSTM. This result illustrates that incorporating computational principles from neuroscience and cognitive science into deep neural networks can enhance adaptability to complex temporal dynamics, mirroring some of the core properties of human learning.},
number={2},
journal={Proceedings of the AAAI Conference on Artificial Intelligence},
author={Kabir, Md Rysul and Mochizuki-Freeman, James and Tiganj, Zoran},
year={2025},
month={Apr.},
pages={1345-1354}
}